大家會不會很好奇跟朋友在LINE上最常講的話是什麼? 或是跟朋友講了幾通電話呢?
前陣子很流行把LINE聊天紀錄傳到分析網站去分析各種數據,
但需要把聊天紀錄傳到該網站><
雖然開發者說不會有個資外洩問題,但是不怕一萬只怕萬一,還是自己寫程式分析最安全~
使用環境
步驟解析
先到LINE下載和想分析對象的對話紀錄(txt檔)
用jieba中文分詞工具將下載的文字檔做中文分詞,找出出現最多次的詞,而不是單字。
去除不需要分析的資料,例如上午、下午、數字(訊息傳送時間)。
將分析結果用cutecharts圖表顯示。
程式碼
#encoding=utf-8
import jieba
import jieba.analyse
from cutecharts.charts import Bar
from cutecharts.charts import Pie
content = open('line.txt', 'rb').read()
words = jieba.lcut(content) # 使用jieba這個library對文檔內容進行分詞
counts = {} # 此為由文字內容對應到出現次數的dictionary
# 進行統計
for word in words:
if len(word) <= 1: # 排除單個字
continue
elif word.isdigit(): # 排除數字
continue
else:
counts[word] = counts.get(word, 0) + 1
# 刪除不重要的詞語
text=' '.join(words)
excludes = {'\r\n','下午','上午','...'} # LINE紀錄會有很多換行,如不去掉分析完會顯示
for exword in excludes:
try:
del(counts[exword])
except:
continue
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根據單詞出現次數進行排序
# 將出現次數最多的幾個詞畫成圖表
top_words = []
top_counts = []
i = -1
while len(top_words) <= 10:
i += 1
word, count = items[i]
if word == "通話" or word == "照片" or word == "影片" or word == "貼圖" or word == "你的名字" or word == "對方名字":
continue
top_words.append(word)
top_counts.append(count)
chart = Bar("關鍵字圖表")
chart.set_options(labels = top_words, x_label="單詞", y_label="出現次數")
chart.add_series("次數", top_counts)
chart2 = Pie("通話/影片/照片數統計")
chart2.set_options(labels=['照片', '影片', '通話'])
chart2.add_series([counts.get("照片", 0), counts.get("影片", 0), counts.get("通話", 0)])
chart3 = Pie("傳送訊息量")
chart3.set_options(labels=['你的名字', '對方'],inner_radius=0)
chart3.add_series([counts.get("你的名字", 0), counts.get("對方名字", 0)])
chart.render(dest="關鍵字.html")
chart2.render(dest="通話/影片/照片數統計.html")
chart3.render(dest="傳送訊息量.html")
成果發表會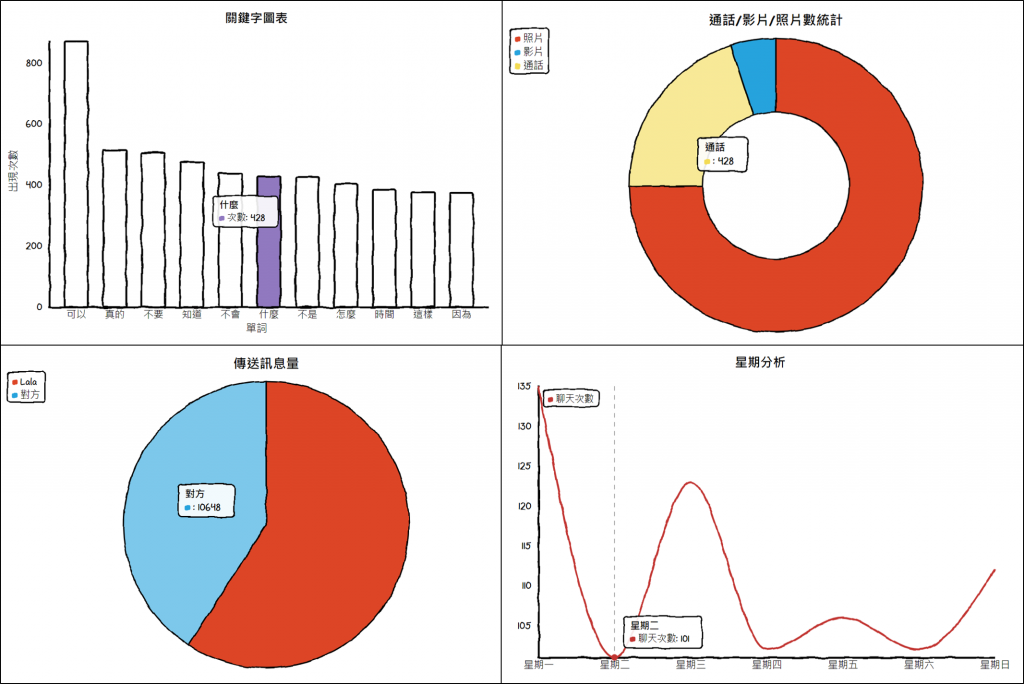
雖然要等個幾秒讓jieba分詞,但是整體速度還是很快,而且自己做出來的感覺也不一樣~


